
OpenLineage is an open-source specification for data lineage. The specification is complemented by Marquez, its reference implementation. Since its launch in late 2020, OpenLineage has been a presence at the BuzzWords Summit in Berlin and has been generating increasing interest. Having personally attended discussions among the developers contributing to this project, let’s explore the challenges and questions they face, the solutions they have chosen, the specification definition, and the ongoing developments.
What is lineage?
Lineage is a set of relationships represented by lines connecting tables to various data processing processes, both input and output. In Marquez, for example, it looks like this:

One of the goals is the identification of duplicates. This is a fundamental feature of any data ingestion architecture, not just in big data. With classifications (tags) like “personal data” or “expiration date” that propagate with the lineage, it becomes possible to automate processes. Without lineage, making a copy of a table might lead to exposing data. In terms of use cases, the primary ones are:
- Reliability, for example, by identifying a source, data, or process as the root cause of an abnormal result.
- Compliance, for example, with the General Data Protection Regulation (GDPR), which requires companies to maintain a register of processing activities for personal data. Such a register can be generated from your platform’s lineage solution because it tracks the data used and the successive processes applied.
In the Hadoop ecosystem, static lineage, which occurs during data creation or import, is achieved with Apache Atlas. In its dynamic aspect, typically when a dataset is the result of a calculation in Apache Spark, Apache Falcon was historically used. Unfortunately, this project was put on hold in 2019 due to low activity. There are alternative solutions to fill this gap. For Spark, solutions like Spline (SPark LINEage) or Open Metadata for broader governance are available. However, lineage is compromised if it doesn’t exist across all infrastructure components. This leaves room for paid solutions that, to date, offer more comprehensive lineage.
How to do it?
Let’s take the analogy of a photographer (figures from the conference). You can infer things by looking at the image, but the simplest approach is to trace the information from the camera, as the EXIF (Exchangeable image file format) standard proposes.

So, the idea is to create a specification with a REST API to produce and consume these metadata. Lineage is no longer reliant on the implementation of many connectors but on a single one, as shown in the following figure. Producers (at the top of the figure) generate information for consumers (at the bottom of the figure) using a common formalism.
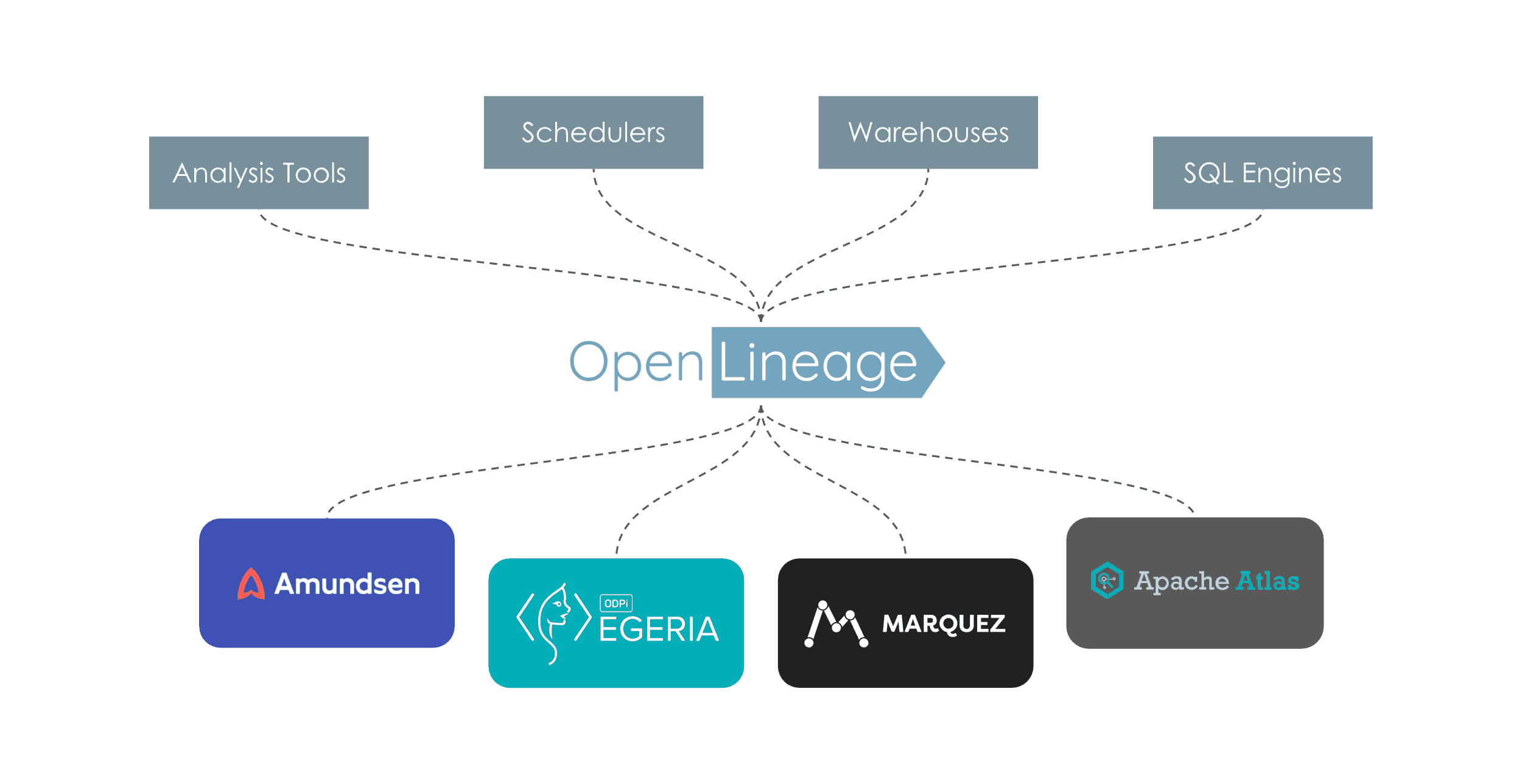
The Specification
The information to be traced is diverse and of various types. There’s the table schema, for example, but also all the details about how the dataset was constructed: which tool, when, by whom…
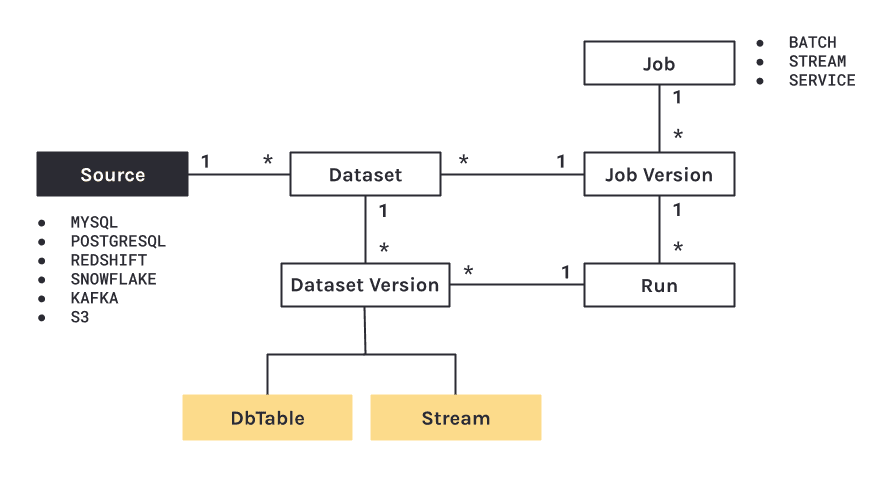
These data are organized in JSON files called “facets.” There are three root facets, but they can be extended with user-defined child facets. These are:
- Dataset facet: the schema, statistics, documentation, both input and output.
- Job facet: for example, the SQL query of the processing or the location of the source code used.
- Run facet: information related to the execution of a task, such as start and end timestamps and any error messages.
This construction approach allows for rapid convergence on a very general “core spec” that is easy to extend. This way, the difficulty related to the granularity of metadata is avoided because considering all the information is the safest way to avoid disagreements among different sponsors.
Work Presented at the BuzzWords Summit
In 2021, the focus was on providing an overall introduction to the project and its contributors. In 2022, there was a first demonstration of the tools. During that year, particular attention was paid to lineage at the column level. Many databases are structured with columns, making lineage creation at this level particularly relevant. This aspect had been previously discussed in a blog post by OpenLineage, and we also witnessed a demonstration of this feature.
To achieve this, a specific facet related to the dataset facet is created. More concretely, each modified column generates the following elements:
- A list of input columns (identified by column name).
- A textual description of the transformation, such as a calculation formula.
- A transformation type (currently “IDENTITY” and “MASKED” exist to describe either unmodified data or data masked via hashing).
For this solution to truly gain traction, it’s essential to enrich the range of transformations and extend this mechanism to the lowest-level data insertion, directly into HDFS, without relying on Hive. These advancements will increase the system’s capabilities and provide a more comprehensive and adaptable solution for users.
Conclusion
In the introduction, we mentioned the existence of competing solutions for lineage; however, this solution has significant strengths that could set it apart:
- The project’s structure is inspired by that of OpenTelemetry. The project offers a specification, an API, an SDK, and tools, with support from the Linux Foundation for OpenLineage.
- The scope is more limited compared to other equivalent products; it’s solely focused on lineage, specifically horizontal lineage. It doesn’t take into account business processes or the company’s organization, which constitute vertical lineage. This narrow focus accelerates progress.
- Additionally, there’s a broader developer vision with a normative triptych: Parquet – Iceberg – OpenLineage. These three open-source projects share developers and common challenges. For example, Iceberg generalizes the use of metadata in Parquet, and OpenLineage implements transformations present in Iceberg (on partitions). Real synergies exist.
With OpenLineage in your software stack, you’ll have a more open and easier-to-maintain system. This standard could establish itself and reignite momentum for open-source data governance tools.
Sources
Berlin BuzzWords conferences:
Other online sources from project contributors:





